If you’re building a book scanner (such as a Decapod or BookLiberator), you might find this information useful:
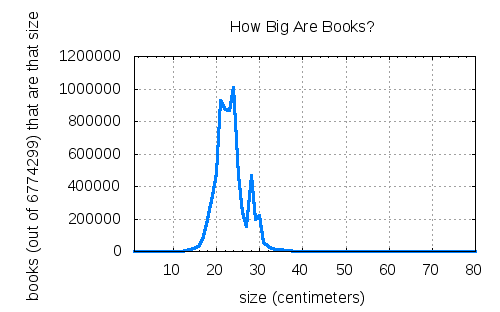
Summary: after surveying 6.7 million books, 30cm seems to be the sweet spot — if your scanner can handle that, then you should be able to scan most books.
Raw data courtesy of the Internet Archive, which hosts book data supplied by the Library of Congress and the Open Library project. See LC’s “Books All” files (to 2006), and the Open Library’s JSON data dump (which includes information from libraries other than LC, from Amazon, etc). The LC data is in MARC format with the size in centimeters in field 300 $c. The OL data has size in the ‘physical_dimensions’ field, in centimeters except as otherwise specified (e.g., “11 x 9.4 x 0.7 inches”).
Try this on for size: If we were concerned solely with “most” books, people like you wouldn’t be up in arms about orphan works.Long tail, anyone?
Lay off the drugs.
Wow. I completely didn’t understand what you are trying to say. Maybe say it again with more words? Thanks.
I think the point he was going for was that the most interesting and important work for diy book scanning is ‘in the margins’ – the more difficult to find things. Which, maybe, could come in stranger sizes.
To provide some insight to the graph above from an Internet Archive perspective.”Large” books do not fit on IA’s scanning hardware well (i.e. large map books etc). They are required to be specially captured by a dedicated and specially trained technician. Hence it’s not a surprise that there are not many books larger than 30cm. Also the cost and care required to transport large books is substantially more than a smaller book. Hence the frequency of large books arriving at IA scanning centers may be low compared to the books in the 15cm to 30cm range. My point being: there may actually be more books in the long tail than the graph conveys. (I do not work for the IA, but have observed their digitization process on a few occasions).
But remember, the Internet Archive is just hosting the data. The data itself doesn’t come from IA; it comes from the Library of Congress and the Open Library project. Even if there is some kind of selection bias going on, the extreme flatness of that tail is pretty convincing. There may be a few very large books out there, but it looks to me like they’re not worth optimizing for when building a mass-market personal book digitizer.
The question is, how does one go about surveying 6.7 million books in the first place?
Seems like a lot of time!
Anne